Ponieważ firmy przetwarzają więcej danych niż kiedykolwiek wcześniej, organizacje muszą być w stanie zmaksymalizować pojemność pamięci masowej i przechowywać jak najwięcej danych bez nadmiernych kosztów. W tym miejscu pojawia się deduplikacja danych. Dzięki tej technice nadmiarowe dane są wykrywane i eliminowane przed zapisaniem kopii zapasowej. Prowadzi to do mniejszego wykorzystania przestrzeni dyskowej, umożliwiając zapisanie nowych danych w ich miejsce. Zapewnia to również wydajne tworzenie kopii zapasowych danych, ponieważ nie trzeba tracić czasu na tworzenie kopii zapasowych duplikatów tych samych danych.
Należy pamiętać, że każdy producent może twierdzić, że jego produkt oferuje określony współczynnik deduplikacji danych. Na przykład, jeden z dostawców może twierdzić, że może zaoferować wskaźnik deduplikacji, który jest 20 razy wyższy niż inne, przewyższając konkurencję o ponad 200%. Na rzeczywisty wskaźnik deduplikacji wpływa jednak wiele zmiennych.
Dowiedzmy się, czym jest deduplikacja danych i jak ocenić współczynnik deduplikacji przy wyborze rozwiązania do tworzenia kopii zapasowych.
Jak obliczyć współczynnik deduplikacji danych?
Aby skutecznie usuwać zduplikowane dane, urządzenie musi być wyposażone w procesory i technologię oprogramowania, która pozwala zaoszczędzić miejsce na dysku.
Podczas korzystania z deduplikacji danych, system identyfikuje bloki danych przed ich zapisaniem. Każdemu blokowi danych przypisywany jest unikalny numer identyfikacyjny, a dla przechowywanych bloków tworzone są tzw. odciski palców. Odciski palców dla przechowywanych bloków są następnie porównywane z nowo zapisanymi blokami danych.
Jeśli wykryty zostanie zduplikowany blok, system generuje indeks, który wskazuje lokalizację zduplikowanych danych. Nadmiarowe dane są następnie usuwane, dzięki czemu można zoptymalizować pojemność pamięci masowej. Ponieważ ryzyko ataków ransomware rośnie z każdym dniem, firmy muszą wdrożyć skuteczny plan tworzenia kopii zapasowych i odzyskiwania danych, aby bezpiecznie przechowywać swoje dane, zapewniając wystarczającą pojemność pamięci masowej za pomocą deduplikacji danych.
Firmy wykazują tendencję do regularnego tworzenia kopii zapasowych dużych ilości danych, co może prowadzić do wzrostu kosztów przechowywania. Nowe lub zmodyfikowane dane zazwyczaj stanowią jedynie niewielki ułamek wszystkich danych, których kopie zapasowe są tworzone. Oznacza to, że wiele danych, których kopie zapasowe są tworzone codziennie, zawiera w rzeczywistości zduplikowane lub nadmiarowe dane. W tym miejscu pojawia się deduplikacja danych.
Aby skutecznie obliczyć współczynnik deduplikacji danych, użytkownicy muszą obliczyć procent zduplikowanych danych, które są ostatecznie usuwane.
Ponieważ każdy dostawca ma tendencję do obliczania współczynników deduplikacji danych w inny sposób, poniżej wyjaśniamy trzy etapy obliczania współczynnika deduplikacji danych. Każdy etap generuje inną wartość:
Etap 1 [Oryginalny zestaw danych]: Całkowita pojemność danych, które muszą zostać zarchiwizowane przed usunięciem nadmiarowych danych.
Etap 2 [Transfer danych po deduplikacji]: Ilość danych, które można przesłać do przechowywania na serwerze po deduplikacji danych.
Etap 3 [Rzeczywiste przechowywane dane]: Ilość danych przechowywanych na serwerze kopii zapasowych.
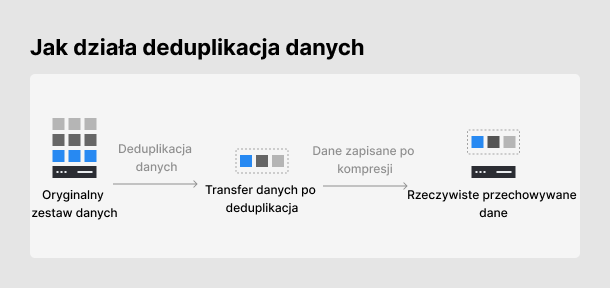
Mierząc wydajność deduplikacji danych, firma Synology zaleca brać pod uwagę Etap 2 [Transfer danych po deduplikacji]. Jeśli analizowalibyśmy wartość wygenerowaną podczas etapu 1 [Oryginalny zestaw danych], może to być mylące, ponieważ zawiera ona zarówno “stare”, jak i “nowe” dane, które są następnie dzielone przez całkowitą ilość zachowanych danych. Niektórzy producenci mogą sztucznie zawyżać tę liczbę, wprowadzając użytkowników w błąd co do tego, który etap jest faktycznie wykorzystywany do pomiaru wydajności deduplikacji danych.
Jak pokazano poniżej, istnieją dwa różne wyniki po obliczeniu wartości. Istnieje duża rozbieżność między nimi, co może prowadzić do nieporozumień, ponieważ firmy mogą źle zrozumieć efekty deduplikacji danych.

Sprawdzając, w jaki sposób produkty naszych konkurentów wykonują deduplikację danych, zidentyfikowaliśmy trzy etapy wymienione powyżej. Dzieląc oryginalny zestaw danych przed deduplikacją przez ilość przestrzeni dyskowej zajmowanej w miejscu docelowym, uzyskalibyśmy wskaźnik redukcji danych na poziomie 95%.
Przedsiębiorstwa powinny jednak skupić się na rozmiarze przesyłanych danych, którego wartość należy podzielić przez ilość miejsca zajmowanego w miejscu docelowym. Używając tego wzoru do obliczenia współczynnika deduplikacji danych, średnia redukcja danych wyniesie około 40-66%.
Przykładowo, tajwańska firma Shiseido była w stanie zwiększyć dostępną pojemność pamięci masowej o 52%, korzystając z technik deduplikacji danych zawartych w rozwiązaniach do tworzenia kopii zapasowych Synology. W porównaniu z innymi firmami oferującymi rozwiązania do tworzenia kopii zapasowych, Synology oferuje rozwiązania w niższej cenie, pozwalając przedsiębiorstwom zaoszczędzić na kosztach pamięci masowej i zmaksymalizować jej pojemność, aby mogły one zabezpieczyć jak najwięcej danych.
Maksymalizacja pojemności pamięci masowej i obniżenie kosztów dzięki deduplikacji danych
Mając na uwadze bolączki przedsiębiorstw, firma Synology wdrożyła technologię deduplikacji danych, dzięki czemu firmy mogą teraz zminimalizować koszty pamięci masowej, jednocześnie maksymalizując jej pojemność.
Firmy mają tendencję do ciągłego tworzenia kopii zapasowych danych przy jednoczenym przechowywaniu ich na swoich urządzeniach. Oznacza to, że jeśli zduplikowane dane nie zostaną usunięte przed zapisaniem danych, spowoduje to zajęcie dodatkowej przestrzeni dyskowej na urządzeniu do tworzenia kopii zapasowych.
Właśnie dlatego firma Synology wdrożyła deduplikację inline podczas wykonywania kopii zapasowych. Zanim jakiekolwiek dane zostaną zapisane, system jednocześnie porówna zawartość danych i dokona ich usunięcia, zmniejszając pojemność pamięci masowej potrzebną do przechowywania danych.
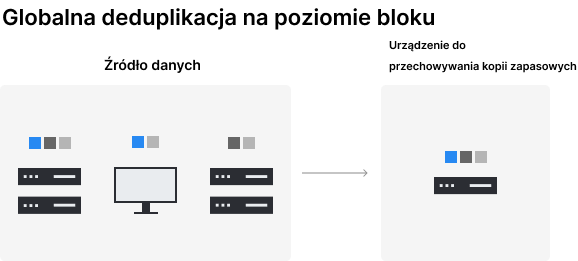
W tym samym czasie Synology wdrożyło również technologię globalnej deduplikacji na poziomie bloków jako sposób na usunięcie zduplikowanych kopii między wieloma źródłami kopii zapasowych. Ma to na celu zapewnienie, że żadne nadmiarowe dane z wielu urządzeń nie zostaną zduplikowane między wieloma zadaniami kopii zapasowych przechowywanymi w ramach jednego folderu współdzielonego. Pomaga to firmom zaoszczędzić przestrzeń dyskową bez wpływu na wydajność tworzenia kopii zapasowych.
Ponieważ dane są prawdziwą kopalnią złota, firmy muszą zrobić wszystko, co w ich mocy, aby bezpiecznie przechowywać swoje dane. Oznacza to, że firmy muszą planować z wyprzedzeniem w miarę własnego rozwoju i wybrać rozwiązanie do tworzenia kopii zapasowych, które spełnia potrzeby skalowalności i rozbudowy oraz obejmuje technologie redukcji pamięci masowej, takie jak deduplikacja danych, w celu zmniejszenia całkowitego kosztu eksploatacji (TCO).
Kliknij tutaj, aby dowiedzieć się więcej.