Narzędzia generatywnej sztucznej inteligencji (GenAI) rewolucjonizują działalność przedsiębiorstw, oferując możliwość szybkiego zwiększania wydajności i rozwiązywania złożonych problemów. Ten ekscytujący potencjał wiąże się jednak z poważnym wyzwaniem: prywatnością danych.
W marcu koreański konglomerat zniósł zakaz korzystania z GenAI, by przywrócić go kilka tygodni później po tym, jak pracownicy udostępnili poufne informacje wewnętrzne, w tym zastrzeżony kod i nagranie ze spotkania. Incydent ten podkreśla, że chociaż organizacje dążą do wykorzystania sztucznej inteligencji w celu zwiększenia produktywności, muszą jednocześnie zarządzać ryzykiem wycieku danych i kontrolować je.
Aby zapobiec takim sytuacjom, jak ta opisana powyżej, podczas korzystania z zaawansowanych technologii sztucznej inteligencji, firma Synology wdrożyła kompleksowe techniki deidentyfikacji i skrupulatne zabezpieczenia w ramach naszego przepływu pracy. Zapewnia to odpowiedzialną obsługę informacji o klientach i utrzymuje wysokie standardy bezpieczeństwa danych i prywatności.
Przeprowadzanie deidentyfikacji w środowisku zgodnym z RODO
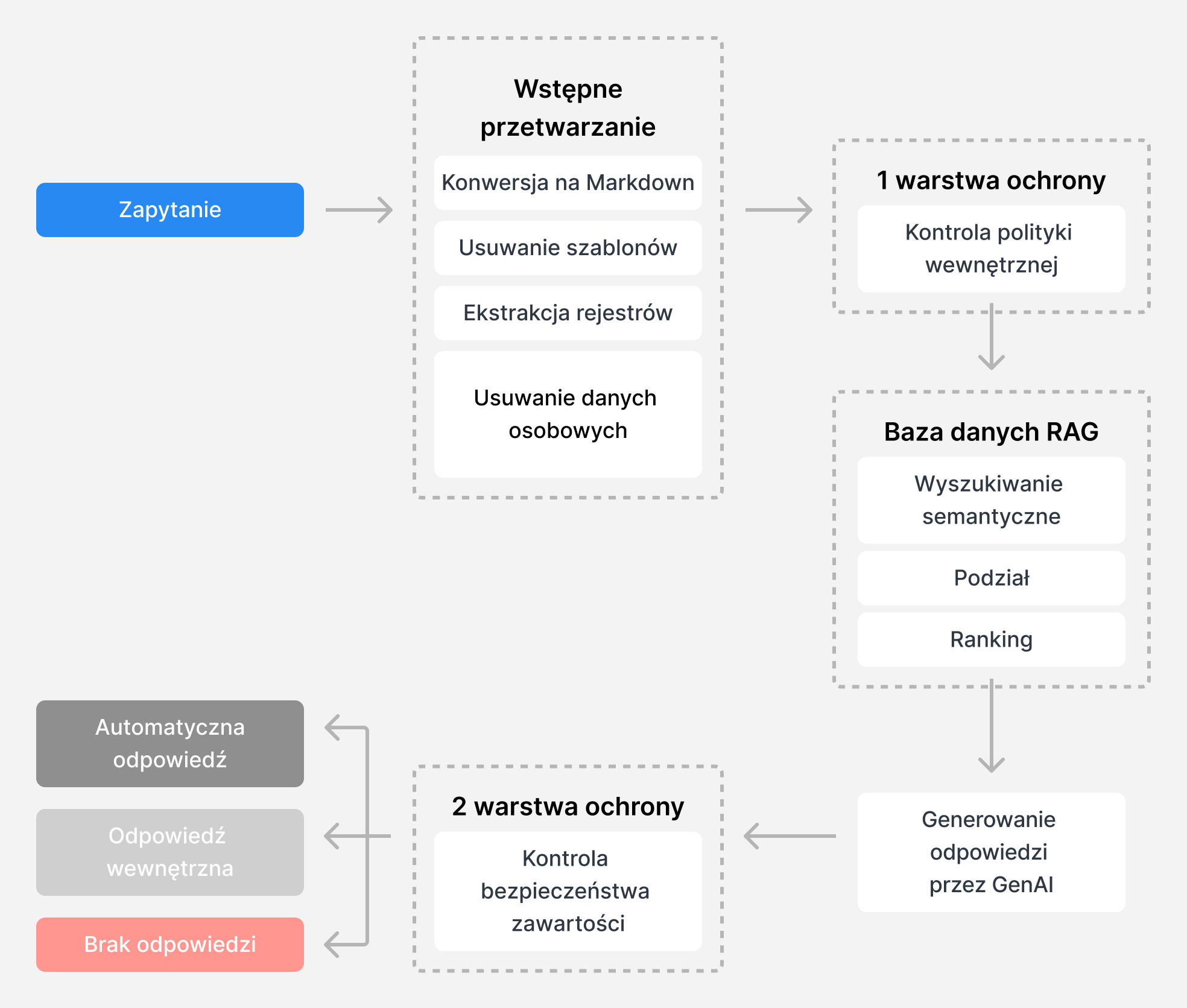
Firma Synology opracowała system Retrieval-Augmented Generation (RAG) w celu zwiększenia wydajności i dokładności naszego wsparcia technicznego. Stworzyliśmy również bazę danych akredytowanych przypadków pomocy technicznej z ostatniego roku, która zapewnia aktualny wgląd w produkty i rozwiązania Synology zatwierdzone przez profesjonalnych inżynierów pomocy technicznej.
Po otrzymaniu nowego zapytania system RAG analizuje jego treść i pobiera odpowiednie rozwiązania z bazy danych, co skutkuje wyższą jakością odpowiedzi w porównaniu do tych generowanych przez GenAI z wykorzystaniem danych publicznych.
System ten jest zbudowany na fundamencie ochrony prywatności klientów dzięki kompleksowemu mechanizmowi deidentyfikacji, który zapewnia, że wszystkie dane z poprzednich zgłoszeń i nowo otrzymanych zapytań są anonimizowane przed ich wykorzystaniem:
- Identyfikacja Regex: Wyrażenia regularne (Regex) identyfikują wzorce, takie jak e-maile i numery telefonów w zgłoszeniach do pomocy technicznej.
- Rozpoznawanie nazwanych jednostek (NER): forma przetwarzania języka naturalnego (NLP) wykorzystywana do identyfikacji i klasyfikacji nazwanych jednostek w tekście na podstawie jego analizy.
- Walidacja sumy kontrolnej: Zapewnia dokładność tych wzorców.
- Ocena kontekstowa: Analizuje otaczający tekst w celu zwiększenia niezawodności wykrywania.
- Techniki anonimizacji: Zabezpieczenie wykrytych poufnych informacji.

Co najważniejsze, ten kompleksowy proces deidentyfikacji jest przeprowadzany w środowisku zgodnym z RODO, zapewniając pełną zgodność z przepisami i anonimizację danych.
Zapobieganie szkodliwym, tendencyjnym lub w inny sposób niepożądanym działaniom za pomocą barier ochronnych
Po ponownym przetworzeniu w celu deidentyfikacji, wszystkie odpowiedzi wygenerowane przez sztuczną inteligencję przechodzą przez dwie kontrole w systemie w celu sprawdzenia zasad bezpieczeństwa, aby zapobiec przypadkowemu ujawnieniu poufnych informacji lub potencjalnie szkodliwych usług doradczych.
- Kontrola zasad wewnętrznych: Pierwsze zabezpieczenie sprawdza naruszenia zasad wewnętrznych lub ryzyko utraty danych przez użytkowników. Na przykład, jeśli zgłoszenie zawiera prośbę o pliki instalacyjne, DSM lub wersje aplikacji, które mogą wpływać na istniejące mechanizmy użytkowników, system przestaje odpowiadać. W przypadku zgłoszeń dotyczących powszechnych luk i zagrożeń (CVE) lub powiązanych z innymi zgłoszeniami wsparcia technicznego, system działa podobnie. W takich sytuacjach dostarcza on podsumowanie głównych faktów, które kierują decyzję do inżyniera wsparcia technicznego w celu ewentualnej eskalacji.
- Kontrola bezpieczeństwa treści: Drugie zabezpieczenie gwarantuje, że wygenerowane odpowiedzi nie zawierają poufnych informacji, takich jak polecenia konsoli, szczegóły zdalnego dostępu lub inne kontekstowo istotne dane, które mogą być niedostępne lub nieodpowiednie w niektórych scenariuszach. Po przejściu przez tę barierę system ostatecznie zdecyduje, czy odpowiedzieć automatycznie, czy też przekazać zgłoszenie personelowi pomocy technicznej do sprawdzenia.
Wnioski
Ten zautomatyzowany przepływ pracy wsparcia opartego na sztucznej inteligencji znacznie zwiększył dokładność i trafność odpowiedzi, poprawiając nasz czas reakcji dwudziestokrotnie. Wdrażając rygorystyczne procesy deidentyfikacji i solidne zabezpieczenia, zapewniamy poufność danych i przestrzegamy ścisłych protokołów prywatności.
Mając doświadczenie w opracowywaniu systemu obsługi klienta opartego na sztucznej inteligencji, w pełni zdaliśmy sobie sprawę z jej potencjału w rozwiązywaniu problemów. Sztuczna inteligencja oferuje potężne możliwości, jednak wymaga odpowiednich mechanizmów kontroli. Musi być także dokładnie weryfikowana, aby działała zgodnie z założeniami i standardami jakości. Jedynie to pomoże w zapewnieniu równowagi między wydajnością a prywatnością. Idąc dalej, Synology dotrzyma swoich zobowiązań dotyczących prywatności i wykorzysta potencjał sztucznej inteligencji, jednocześnie chroniąc cenne dane klientów.