Synology 是一間提供儲存解決方案公司,主要銷售資料儲存、檔案管理、資料備份、影像監控等解決方案,目前在全球有超過 1,300 萬台設備的佈建。隨著龐大的客戶數量而來的是每年 28 萬張的技術支援案件表單,內容橫跨簡單的使用提問、設定、到企業複雜的 IT 環境內的相容性。如何維持高品質而且快速的客戶服務,一直是 Synology 的重要目標,因此,早在四、五年前 Synology 就成立 AI 小組,使用機器學習的技術在使用者提問的時候推薦相關的參考資料給使用者,讓每年約四分之一的技術支援案件可以快速地得到解決。
隨著近年生成式 AI 模型逐漸成熟,我們開始思考如何將它應用在客戶服務上。然而,大型語言模型(Large Language Model, LLM)雖然可以滿足生活中絕大多數的需求,卻很難直接使用於技術支援服務。首先,LLM 的訓練資料來源眾多,因此在回答時可能會參考來自第三方論壇、社群平台等資訊而造成混淆,得出未必最正確的結論;其次,客戶服務會牽涉到客戶隱私、操作風險、合規等議題,LLM 很難精準地判斷。所以,要將 LLM 使用在客戶服務上,勢必得經過一連串的設計和調校。
Synology 選擇使用的策略是 RAG(Retrieval-Augmented Generation),是一種結合了搜尋、檢索、和自然語言的生成能力的模型,從特定的資料庫擷取相關資訊作為回答的基礎,再根據擷取出的資訊生成內容。這麼做的好處是可以得到與資料庫品質相當的精準回答,避免答案資料過時、在不同領域間混淆、沒有答案時回答錯誤資訊等 LLM 的已知問題,同時無須大費周章重新訓練一個 LLM。
決定了策略以後,我們將整個專案分割成四個部分──資料預處理、客戶意圖分析、資料庫檢索、和生成回應──並開發相應的系統依序處理。
資料預處理:客戶隱私是第一優先議題
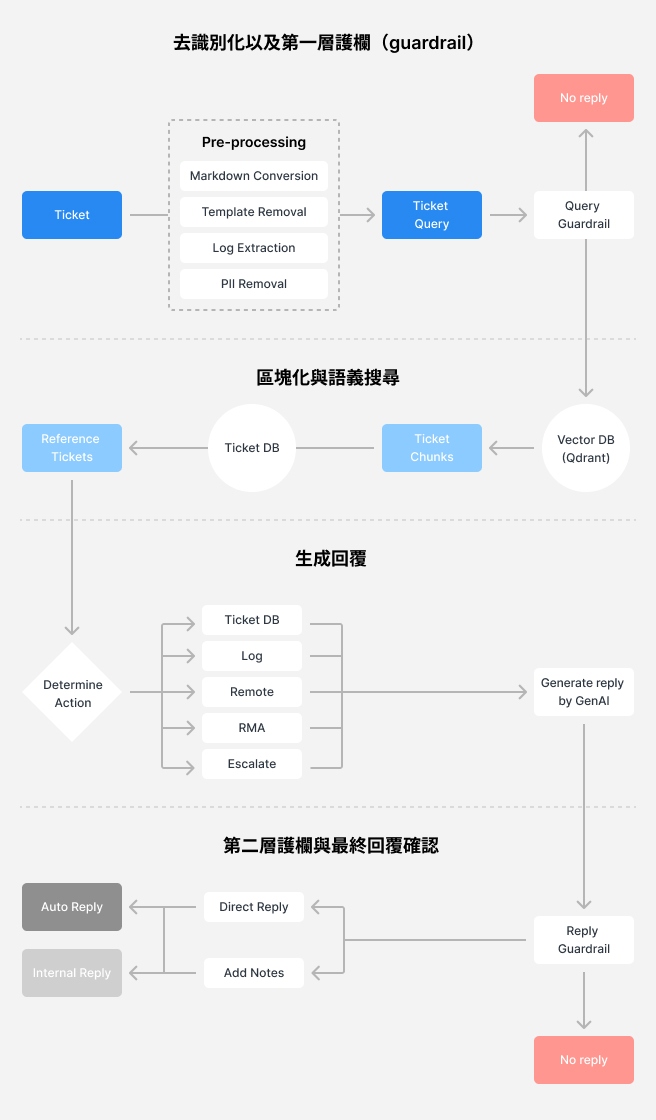
資料的預處理相當於料理中的「備料」階段,RAG 模型資料庫中的資料品質對於生成內容扮演著至關重要的角色。這個階段的主要目標有兩個:資料的去識別化(de-identification)和分段(chunking),前者是為了確保用於參考的資料不會包含任何客戶的隱私,後者是讓系統「看得懂」參考資料以利於擷取。
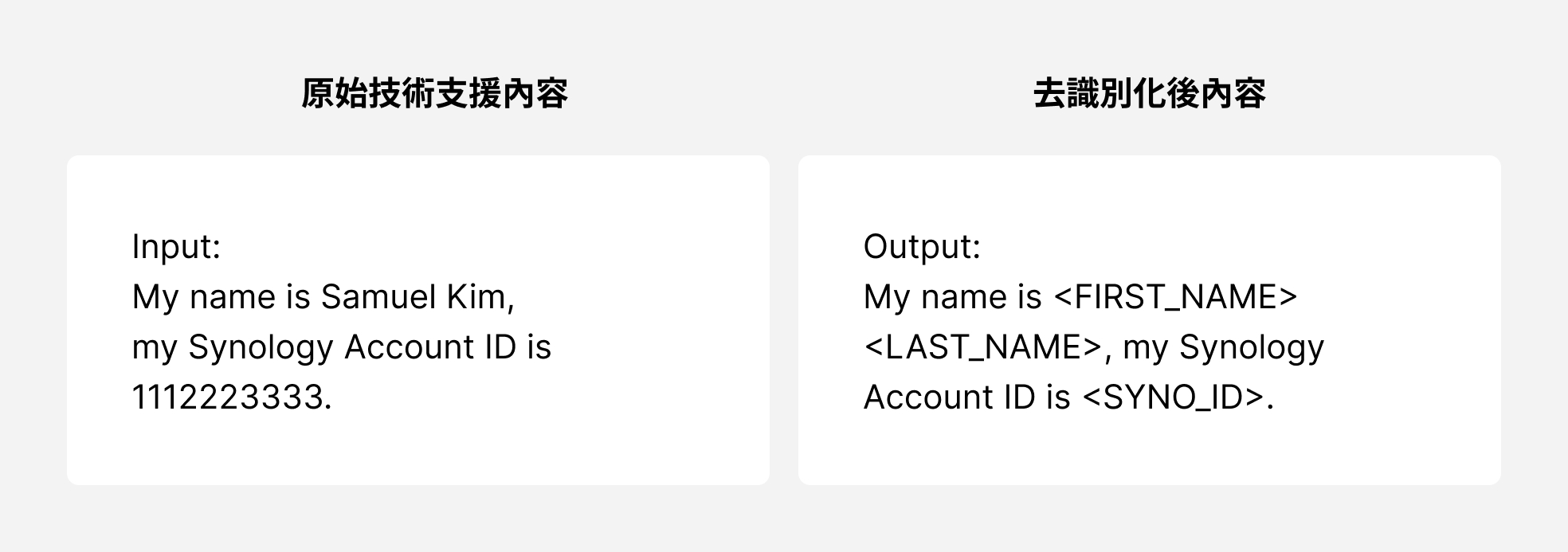
我們提取了 Synology 過去一年所有高品質的客戶服務回應,並先針對這些內容去識別化,首先,我們針對資料用 Regular Expression(Regex),找出 email、電話等資料格式並以無法識別的資料替換。其次,使用 Named Entity Recognition(NER)識別文本中的各種可能辨識出的各種名稱。最後,再透過機器學習的方式讓系統能夠自動精準判別出可能識別出客戶的情境資料,最後再反覆驗證確認完全不含隱私資訊。去識別化後的資料會再進行分段,並針對文字內容語意進行向量化(semantic embedding)索引,儲存於資料庫,讓後續系統可以快速地進行相似度搜尋。
客戶意圖分析:決定系統要如何處理每一則案件
當收到客戶技術支援需求的時候,系統的第一步會先分析客戶的意圖,以決定下一步如何處置案件。舉例來說,如果客戶的需求牽涉到必須技術支援顧問人為處理的部分,像是客戶主動要求遠端連線診斷或排除障礙,就不需要再經過 AI 先提供解答。系統同樣會先將客戶資料去識別化,再透過自然語言處理(NLP) 技術來分析客戶意圖。
意圖分析階段是否有效率的關鍵是建立回應策略的準則,以客戶服務來說,首要目標是定義出系統在不同客戶意圖下的回應策略,並建立在什麼樣的條件下系統應該轉接服務專員、請客戶補充更多資訊、或是直接擷取資料庫內容生成的準則。
資料庫檢索:結合語意搜尋和傳統統計搜尋
當獲取了客戶的意圖,並排除了不適用 RAG 的情況之後,就進入資料庫檢索階段,這個階段系統會先重新生成問題成精準的描述,再進一步使用混合搜尋技術(Hybrid Search),結合語意搜尋和傳統統計基礎搜尋,從資料庫中提取相關的歷史支援紀錄和知識庫內容。這些檢索結果會作為回答的基礎參考資料,確保生成的回應準確且具參考價值。
值得注意的是,資料分段的品質會很大程度地決定搜尋結果的品質,依照我們的經驗,資料分段最好保留較多部份的情境資料,讓每一段資料有一部分的重疊,搜尋出來的結果才會更符合客戶意圖。此外,雖然業界普遍採取的做法是結合語意和傳統統計搜尋的混合搜尋技術,但根據不同的搜尋意圖和資料庫,兩種搜尋結果的準確率也會有很大的落差,因此實務上,我們也正在規劃額外建立 Re-ranking 模型,將搜尋到的結果根據深度學習計算出來的相似度重新排序。
生成回應:回覆前仍須經過重重把關
最後,系統會根據擷取出來的知識庫內容,再對 LLM 下指令生成適合的回答。雖然生成的過程相對單純,但這個階段最重要的任務是建立準則(Guardrail),把關回覆的答案是否恰當。在 Synology 的 RAG 系統中,生成出的回覆內容會經過一連串的檢查,先過濾掉包含風險的指令(如要求客戶遠端連線、或下控制台指令的內容,都不能直接回覆,必須再經過工程師人工驗證)、或不恰當的建議(如要求客戶重複已經嘗試過的故障排除操作)等。
整個系統的訓練過程中,我們也按部就班地設定階段性的目標。第一階段,系統生成的回覆僅提供內部客服人員作為參考,最終由客服人員判斷內容是否符合規範、是否精準回答客戶問題,再選擇發出;到第二階段,逐步放寬為部分已經過反覆驗證的常見問題,允許系統直接回覆客戶;到未來,我們希望系統能應用在絕大多數不需要技術人員介入的單純問答案件。
透過這個 RAG 系統,我們成功協助技術支援團隊大幅降低提供服務所需的時間。在今年 6 月份將系統上線以後,初步成果是可以將回應客戶的時間從原本的一天內 (約 22 小時) 有效縮短至 0.5 小時。透過建立 RAG 系統,我們不但大幅縮簡了佈署單純的客戶案例收到回覆的時間,同時更讓技術支援工程師專注在需要詳細診斷和介入的複雜案例,並且讓 IT 環境較複雜的客戶能夠分配到更多的工程師直接服務,達成三贏的局面。