Gli strumenti di Generative AI (GenAI) stanno rivoluzionando le operazioni aziendali, offrendo la possibilità di aumentare rapidamente l’efficienza e risolvere problemi complessi. Tuttavia, questo potenziale entusiasmante porta con sé una sfida significativa: la privacy dei dati.
A marzo, un conglomerato coreano ha revocato il divieto di utilizzo di GenAI, per poi ripristinarlo poche settimane dopo, dopo che i dipendenti avevano condiviso informazioni interne sensibili, tra cui codice proprietario e la registrazione di una riunione. Questo incidente evidenzia che, mentre le organizzazioni mirano a sfruttare l’IA per aumentare la produttività, devono contemporaneamente gestire e controllare i rischi di perdita di dati.
Per prevenire situazioni simili e sfruttare le tecnologie AI avanzate, Synology ha implementato tecniche di de-identificazione complete e rigorosi controlli nel proprio flusso di lavoro. Ciò garantisce una gestione responsabile delle informazioni dei clienti e mantiene elevati standard di sicurezza e privacy dei dati.
Esecuzione della de-identificazione in un ambiente conforme al GDPR
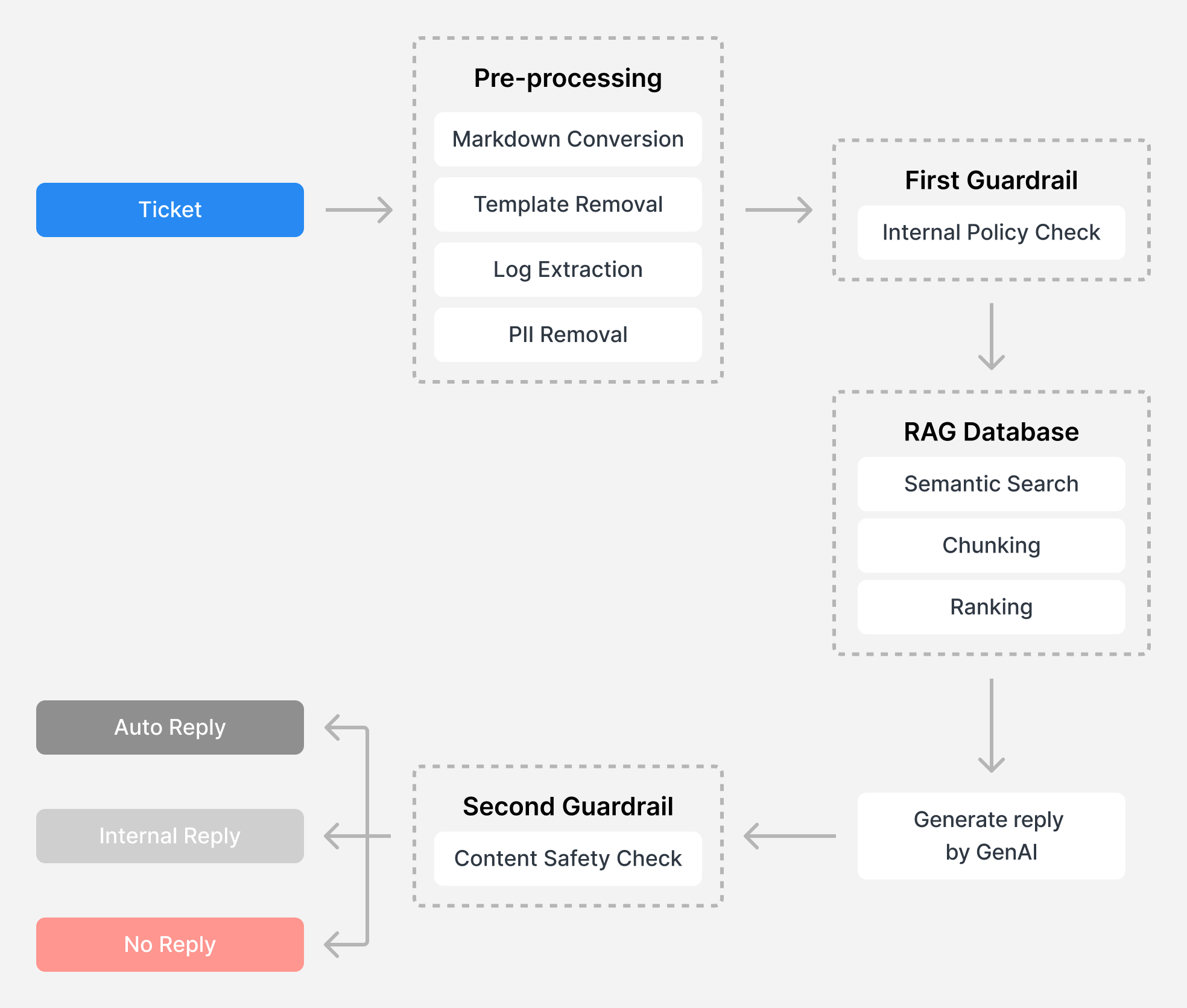
Synology ha sviluppato un sistema di Retrieval-Augmented Generation (RAG) per migliorare l’efficienza e l’accuratezza del supporto tecnico. Abbiamo anche creato un database di casi di supporto accreditati dell’ultimo anno, che fornisce informazioni aggiornate specifiche sui prodotti e le soluzioni Synology approvate da ingegneri di supporto tecnico professionisti.
Quando viene ricevuta una nuova richiesta, il sistema RAG analizza la domanda del cliente e recupera le soluzioni pertinenti dal database, producendo risposte di qualità superiore rispetto a quelle generate da GenAI addestrato su dati pubblici.
Questo sistema si basa sulla protezione della privacy dei clienti con un meccanismo completo di de-identificazione che garantisce che tutti i dati dei casi passati e dei nuovi ticket ricevuti vengano resi anonimi prima di essere utilizzati:
-
Identificazione Regex: le espressioni regolari (Regex) identificano modelli come e-mail e numeri di telefono nei ticket di supporto.
-
Riconoscimento di entità denominate (NER): implementato con l’elaborazione del linguaggio naturale per rilevare entità comprendendone il contesto.
-
Validazione checksum: garantisce l’accuratezza di questi modelli.
-
Analisi del contesto: analizza il testo circostante per aumentare l’affidabilità del rilevamento.
-
Tecniche di anonimizzazione: proteggono le informazioni sensibili rilevate.

Ancora più importante, questo completo processo di de-identificazione viene eseguito in un ambiente conforme al GDPR, garantendo la completa conformità normativa e l’anonimizzazione dei dati.
Prevenire risultati dannosi, distorti o altrimenti indesiderati con controlli
Dopo la rielaborazione per la de-identificazione, tutte le risposte generate dall’intelligenza artificiale passano attraverso due controlli di sicurezza nel sistema per impedire la divulgazione involontaria di informazioni sensibili o consigli potenzialmente dannosi.
-
Controllo delle policy interne: il primo controllo verifica le violazioni delle policy interne o eventuali rischi di perdita di dati per gli utenti. Ad esempio, se un ticket richiede file di installazione, versioni di DSM o dell’applicazione che potrebbero avere un impatto sugli ambienti esistenti degli utenti, assistenza con problemi di vulnerabilità ed esposizioni comuni (CVE) o fa riferimento ad altri ticket di supporto, il sistema smette di rispondere e fornisce un riepilogo dei principali fattori che guidano la decisione al tecnico del supporto tecnico per una potenziale escalation.
-
Controllo di sicurezza del contenuto: il secondo controllo assicura che le risposte generate non forniscano informazioni sensibili come comandi della console, dettagli di accesso remoto o altri dati contestualmente accurati che potrebbero non essere disponibili o inappropriati in determinati scenari. Dopo aver superato questo controllo, il sistema deciderà in ultima analisi se rispondere automaticamente o inoltrare il ticket al personale di supporto per la revisione.
Conclusione
Questo flusso di lavoro di supporto automatizzato basato sull’intelligenza artificiale ha migliorato significativamente l’accuratezza e la pertinenza delle risposte, migliorando i nostri tempi di risposta di venti volte. Implementando rigorosi processi di de-identificazione e robuste protezioni, garantiamo la riservatezza dei dati e aderiamo a rigidi protocolli sulla privacy.
Grazie alla nostra esperienza nello sviluppo del sistema di assistenza clienti basato sull’intelligenza artificiale, abbiamo pienamente compreso che, sebbene l’intelligenza artificiale abbia potenti capacità di risoluzione dei problemi, deve essere completamente limitata da meccanismi di controllo e revisione per garantire un equilibrio tra efficienza e privacy. In futuro, Synology continuerà a mantenere i propri impegni prioritari verso la privacy e a sfruttare il potenziale dell’AI proteggendo al contempo i preziosi dati dei clienti.