Mit weltweit 13 Millionen Installationen bearbeiten wir jährlich rund 280.000 Support-Anfragen – von einfachen Produktfragen bis hin zu komplexen Konfigurationsanfragen in IT-Umgebungen von Unternehmen. Um einen schnellen und qualitativ hochwertigen Kundenservice zu gewährleisten, haben wir vor vier Jahren ein KI-Team aufgebaut. Dieses nutzt maschinelles Lernen, um Nutzern relevante Referenzmaterialien zu empfehlen. So können etwa 50.000 unserer Supportfälle pro Jahr schneller gelöst werden.
Mit der Einführung von großen Sprachmodellen (engl. Large Language Models, kurz LLMs) wie GPT-3 im Jahr 2020 und ChatGPT Ende 2022 eröffnete sich eine neue Dimension im Bereich der Sprachverarbeitung, und bot weiteres Potenzial für die Weiterentwicklung unserer Supportsysteme.
LLMs lösen die Probleme im Kundenservice nicht allein
Obwohl große Sprachmodelle an Popularität gewonnen haben, sind sie für unsere Support-Anfragen nicht direkt geeignet. Ihre Trainingsdaten stammen aus verschiedenen Quellen wie Foren und älteren Artikeln, was nicht immer aktuelle oder präzise Informationen liefert. Zudem fehlt ihnen oft das spezifische Fachwissen, das für manche Anfragen erforderlich ist. Für eine qualifizierte Antwort müssen wir den Kontext sowie unseren Support-Standards berücksichtigen.
Hier kommt die Retrieval-Augmented Generation (RAG) ins Spiel. Diese Technik verbessert die Genauigkeit von KI-Antworten, indem sie auf externe, autorisierte Datenbanken zugreift und damit Kontextinformationen liefert. So können Antworten sowohl präzise als auch richtlinienkonform gestaltet werden.
In 4 Schritten zu einer guten, datenschutzkonformen Support-Antwort
Unser auf RAG basierendes Supportsystem ist in eine vierstufige Struktur gegliedert, um den Datenschutz, die Genauigkeit und die Effizienz sicherzustellen.
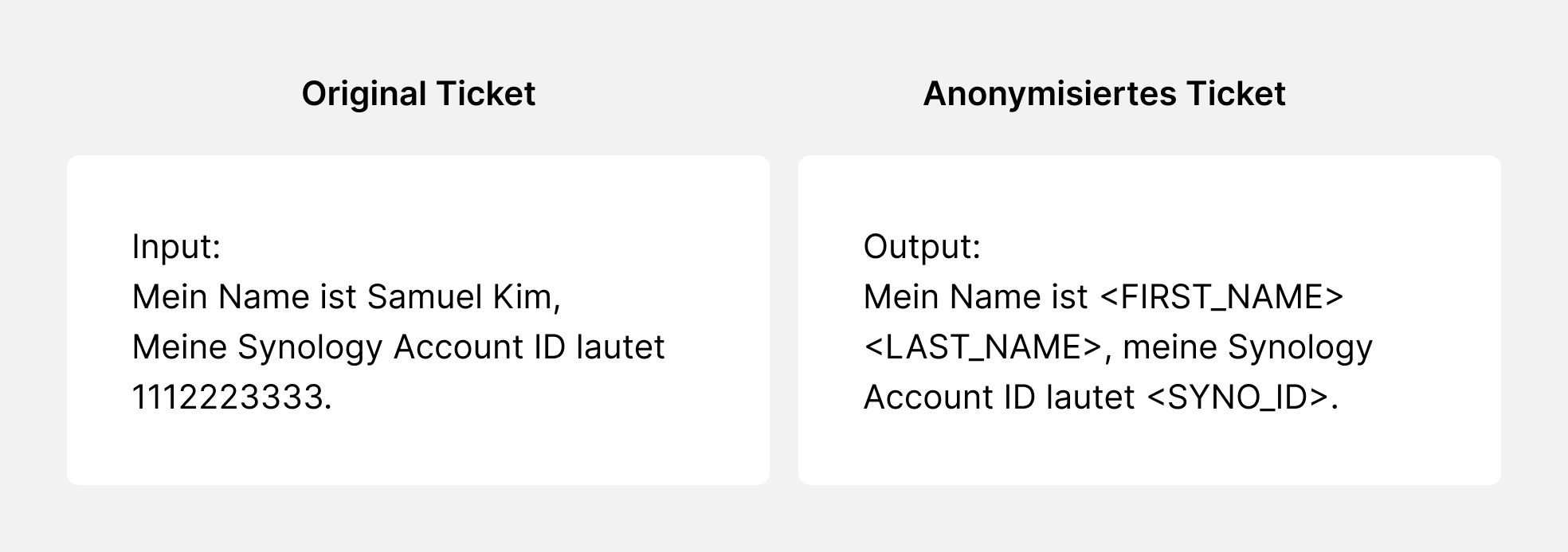
1. Aufbau einer anonymisierten Datenbank
Im 1. Schritt bauen wir eine RAG-Datenbank auf, in der wir historische Supportdaten von vor einem Jahr bis zum heutigen Tag verwenden. Dieser entscheidende Schritt beinhaltet einen De-Identifizierungsprozess, das heißt, die Daten werden gründlich anonymisiert, um die Privatsphäre unserer Kunden zu schützen.
2. Daten bündeln und indexieren
Nach der Anonymisierung unterteilen und indexieren wir die Daten, damit sie effizienter verarbeitet werden können. Zusätzlich versehen wir die Datenabschnitte mit semantischen Einbettungen, was fortschrittliche semantische Ähnlichkeitssuchen ermöglicht. Dabei ist es aus unserer Erfahrung hilfreich, bei der Segmentierung mehr Kontextdaten zu behalten und eine leichte Überlappung zwischen den Segmenten zuzulassen. So erhalten wir Suchergebnisse, die besser mit den Absichten der Kunden übereinstimmen.
3. Support-Ticket analysieren & Informationen suchen
Wie wir der KI beibringen, Kundenbedürfnisse zu „verstehen“
Der nächste Schritt umfasst die Bearbeitung neuer Support-Tickets. Wenn ein Kunde ein Ticket einreicht, anonymisieren wir zunächst sensible Informationen zum Schutz seiner Privatsphäre. Anschließend analysieren wir das Ticket, um die Intention des Kunden zu erkennen und festzustellen, ob eine Antwort durch die KI notwendig ist. Zum Beispiel: Wenn der Kunde spezifisch nach einem Support-Berater fragt, ist keine KI-Antwort erforderlich.
In der Absichtsanalyse ist es entscheidend, die Antwortkriterien festzulegen. Diese bestimmen, wann das System entweder an einen Spezialisten übergibt, den Kunden nach weiteren Informationen fragt oder direkt Inhalte aus der Datenbank generiert.
Sobald die KI den Kontext vollständig erfasst hat, wird eine Suchfunktion aktiviert. Die Frage des Kunden wird so umformuliert, dass die Suche in unserer RAG-Datenbank optimiert wird. Wir nutzen dabei auch semantische Suchmethoden, die es uns ermöglichen, relevante frühere Tickets zu extrahieren und damit einen fundierten Kontext für die Antwort zu bieten.
Die Qualität der Suchergebnisse hängt stark von unserer Segmentierungsstrategie ab. Deshalb entwickeln wir ein fortschrittliches Re-Ranking-Modell, das mithilfe von Deep Learning die Suchergebnisse anhand berechneter Ähnlichkeitsscores neu ordnet. Dieser zusätzliche Verarbeitungsschritt soll die Relevanz und Genauigkeit der bereitgestellten Informationen weiter steigern und unsere Fähigkeit verbessern, die Kundenbedürfnisse präzise zu erfüllen.
4. Richtlinienkonforme Antworten mit menschlicher Kontrolle erstellen
Im letzten Schritt wird aus den verarbeiteten Informationen eine Antwort generiert. Diese Antwort wird dann einer Reihe von Richtlinienprüfungen und weiteren Kontrollmechanismen unterzogen, um sicherzustellen, dass keine sensiblen Informationen wie Konsolenbefehle, Remote-Zugangsdaten oder andere möglicherweise unpassende Inhalte weitergegeben werden. Diese Prüfungen helfen, die Sicherheit zu wahren und sicherzustellen, dass die Antworten im Rahmen des unterstützenden KI-Services bleiben.
Am Ende hilft eine Kontrollinstanz dabei zu entscheiden, ob die generierte Antwort automatisch an den Kunden geschickt werden kann. Falls das System feststellt, dass ein Support-Mitarbeiter eingreifen sollte, wird die KI-gestützte Antwort an das Support-Team weitergeleitet. Die Mitarbeiter prüfen dann, ob die Antwort passend und korrekt ist, bevor sie an den Kunden gesendet wird.
20x schnellere Routine-Antworten. Mehr Ressourcen für komplexe Fälle
Durch diese Architektur können wir Generative KI nutzen und gleichzeitig die hohen Standards an Genauigkeit und Sicherheit wahren, die unsere Kunden erwarten.
Während wir unser System weiter verfeinern, legen wir den Fokus darauf, Antworten noch präziser und kontextgerechter zu gestalten. Wir werden uns weiterhin an die regionalen Unterschiede bei Produktpräferenzen, gemeinsamen Problemen und Compliance-Richtlinien anpassen. So stellen wir sicher, dass unsere KI-generierten Vorschläge technisch korrekt sind und mit den lokalen Vorschriften und Praktiken übereinstimmen.
Indem wir LLM und RAG nutzen und gleichzeitig die Antworten auf Routineanfragen automatisieren, haben wir bis zu 20 Mal schnellere Antwortzeiten. Damit können mehr Mitarbeiter unseres Support-Teams schwierigere und dringendere Probleme bearbeiten, die menschliche Unterstützung erfordern. Dies hilft uns, effizienter zu arbeiten und gleichzeitig unseren Kunden die hochwertige, persönliche Hilfe zu bieten, die sie von unserem Support-Team erwarten.