As businesses are creating more data than ever before, organizations must be able to maximize storage capacity and store as much data as possible without overspending. This is where data deduplication comes in. By using this technique, redundant data is spotted and eliminated before being backed up. This leads to less storage space being used, allowing you to save new data in its place instead. This also ensures that you can efficiently back up your data as you don’t need to spend time backing up duplicate copies of the same data.
Keep in mind that each vendor might claim that their product offers a certain data deduplication ratio. For instance, a vendor might claim that they can offer a deduplication rate that is 20 times higher than others, surpassing competitors by over 200%. However, many variables tend to affect the actual deduplication rate.
Let’s find out what data deduplication is and how to evaluate the deduplication ratio when selecting a backup solution.
How to calculate the data deduplication ratio
To effectively remove duplicate data, your device has to be equipped with CPUs and software technology that allows you to save storage space.
When using data deduplication, the system identifies blocks of data before storing it. Each block of data is assigned a unique identifier number, while fingerprints are created for the stored blocks. The fingerprints for the stored blocks are then compared against newly written blocks of data.
If a duplicate block is detected, the system generates an index, which points to the location of the duplicate data. The redundant data is then removed so that storage capacity can be optimized.
As the risk of ransomware attacks increases every day, businesses must implement an effective data backup and recovery plan to securely store their data, ensuring that they have enough storage capacity with the help of data deduplication.
Businesses tend to back up large amounts of data regularly, which could lead to an increase in storage costs. New data or modified data usually only accounts for a tiny fraction of the total backed up data. This means that a lot of data that is backed up daily actually contains duplicate, or redundant data. This is where data deduplication comes in.
In order to effectively calculate the ratio of data deduplication, users must calculate the percentage of duplicate data that is ultimately deleted.
As each vendor tends to calculate data deduplication rates differently, we explain the three stages of calculating the ratio of data deduplication below. Each stage generates a different value:
Stage 1 [Original data set]: The total capacity of the data that needs to be backed up before the redundant data is removed.
Stage 2 [Data transfer size]: The amount of data that can be transmitted to be stored on a server.
Stage 3 [Actual stored data]: The amount of data stored in the backup server.
When measuring the efficiency of data deduplication, Synology recommends looking to Stage 2 [Data transfer size]. If you look at the value generated during Stage 1 [Original data set], this can be misleading as it contains both the “old” and “new” data, which is then divided by the total amount of data that is retained. Some vendors may artificially inflate this number, confusing users as to which stage the vendor actually uses to measure the efficiency of data deduplication.
As shown below, there are two different results after calculating the numbers. There is a large discrepancy between the two which could lead to confusion as businesses could misunderstand the effects of data deduplication.

When looking into how our competitors’ products perform data deduplication, we found the three stages listed above. Divide the original data set before deduplication with the amount of storage space taken up at the destination for a 95% data reduction rate.
However, enterprises should focus on the size of the transmitted data, which should be divided by the amount of storage space taken up at the storage destination. When using this formula to calculate the data deduplication rate, the average data reduction will be roughly 40~66%.
As an example, Taiwan Shiseido was able to increase storage capacity by 52%, using data deduplication techniques included with Synology’s backup solutions. Compared to other backup vendors, Synology offers solutions at a reduced rate, allowing businesses to save on storage costs and maximize their storage capacity so that they can safeguard as much data as possible.
Maximize storage capacity and lower your costs with data deduplication
By keeping enterprise pain points in mind, Synology implemented data deduplication technology so that companies can now minimize their storage costs while maximizing their storage capacity.
Companies tend to back up data continuously while storing data on their storage device. This means that if the duplicate data isn’t removed before the data is written in, this will create a temporary storage space on the backup appliance.
This is why Synology implemented inline deduplication when performing backups. Before any data is written in, the system will simultaneously compare the content of the data and perform deletions, reducing the storage capacity needed to store the data.
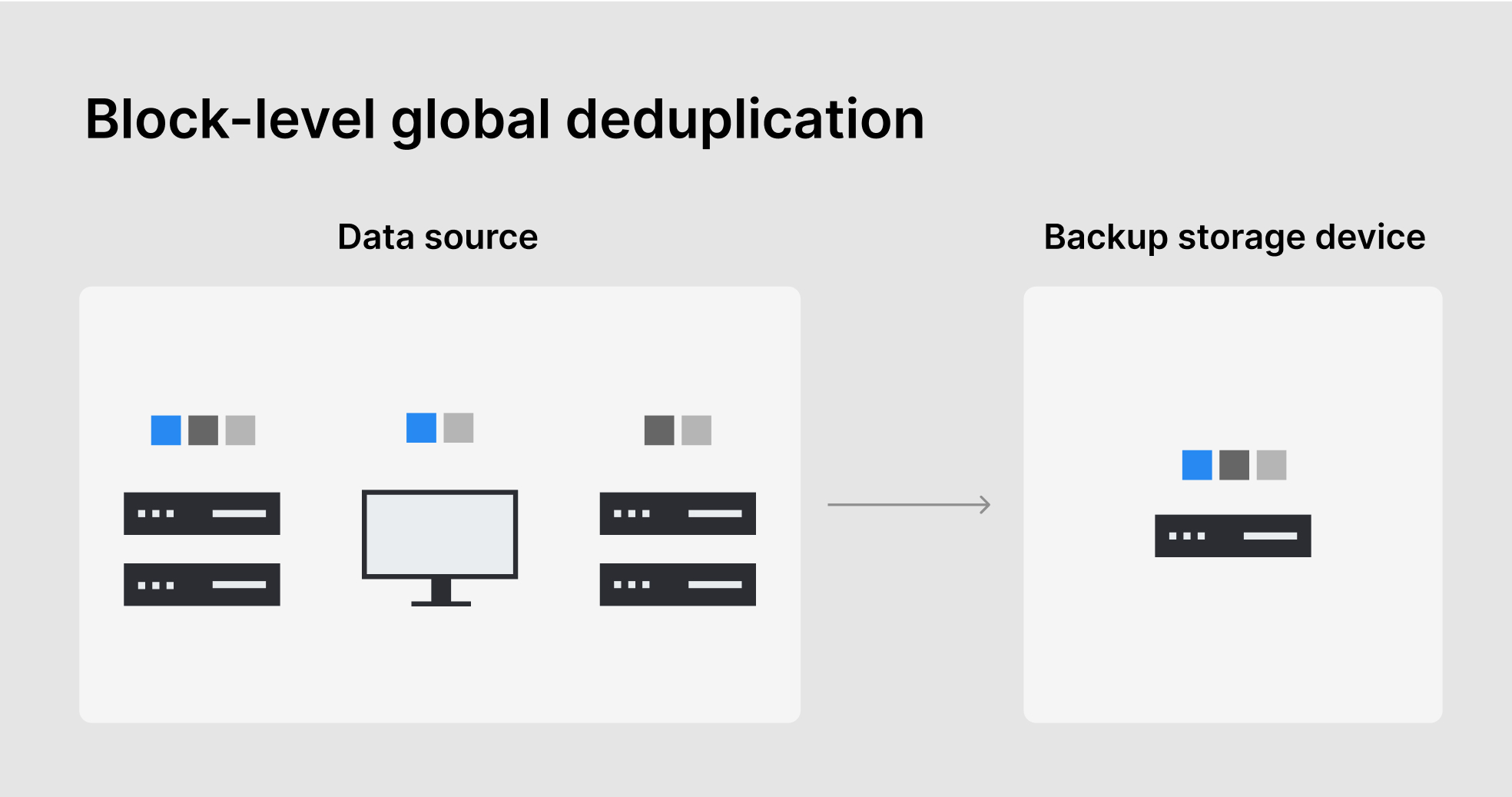
At the same time, Synology also implemented block-level global deduplication technology as a way to remove duplicate copies between multiple backup sources. This is to ensure that no redundant data remains between multiple backup tasks within a single folder. This helps businesses save on storage space without affecting backup performance.
As data is a gold mine, businesses must do everything they can to securely store their data. This means that companies need to plan ahead as they evolve and select a backup solution that meets scalability and expansion needs and includes storage reduction technologies such as data deduplication to reduce total cost of ownership (TCO).
Click here to find out more.