Even 11 nines are not immune to human error
With more businesses moving their mission-critical data to the cloud, it is essential that the cloud platform delivers high levels of availability and durability, making sure your data remains accessible and intact whenever you need it.
“Designed to provide 99.999999999% durability and 99.99% availability of objects over a given year.” Amazon S3 quotes the number of nines (“9s”) as the metrics for the level of data protection and operational performance.
Yet there seems to be an arms race going on among major cloud providers with each trying to reach as many nines as possible. Microsoft Azure boasts 12 nines, while Amazon S3, Backblaze, and Google Cloud Platform tout 11 nines. But the tricky part is that there’s no agreed-upon formula as to how to calculate these numbers. Before we go into details, let’s start with some basics as to what these 9s mean.
Data durability: the ability to keep the stored data consistent, intact without the influence of bit rot, drive failures, or any form of corruption. 99.999999999% (11 nines) durability means that if you store 10 million objects, then you expect to lose an object of your data every 10,000 years.
Service availability: the ability to ensure continuous, non-disruptive service (i.e., uptime) against power outages or system failures. If an SLA (service-level agreement) promises you 99.99% availability, it means that you may experience downtime for approximately 53 minutes a year.
Unlike service availability that can be calculated using the simple formula: Availability (%) = uptime / total time (uptime + downtime), it is much more complex when it comes to data durability. The following are three key factors we should know before we do the math:
1. AFR (Annualized failure rate): The average failure rate in a given year. It is calculated with the following equation: AFR = (24 * 365) / MTBF (hr). MTBF (Mean time between failures) refers to the average time during which a device functions before it reaches the end of life.
2. MTTR (Mean time to repair): It refers to the average time required to bring a system back to its normal operation after a failure. MTTR is one of the key metrics since data durability is all about the probability of another drive failure during the rebuild.
3. Erasure coding (Reed-Solomon codes): A data protection method that splits an object into fragments with an m+n stripe layout (m: data fragments, n: parity fragments). These fragments are evenly distributed across a storage pool. Take a 12+3 erasure coding scheme as an example. It means that the stored object can tolerate a maximum of 3 corrupted fragments, and you’ll need a minimum of 12 fragments to recover your data.
Inside the gray area
Though there is no consensus on how to calculate data durability, there are two formulas available in the cloud storage industry.1
This is what the first formula looks like:
1 – (AFR / (365 / MTTR)) ^ (# of parity)
Suppose the fault tolerance of 4 drives with an AFR at 5% and MTTR of 3.4 days, then the probability of the occurrence of four drive failures when a failed drive is being rebuilt equals:
(AFR * MTTR)4 = (.05/year * 3.4 days * 1/365 year/days)4 = 4.66 * 10-4)4 = 4.7 * 10-14
Then the data durability equals:
1 – (4.7 * 10-14) = .9999999999999530 (13 nines)
The second formula below follows the Poisson distribution, which is used to express the probability of the number of events occurring in a given period.
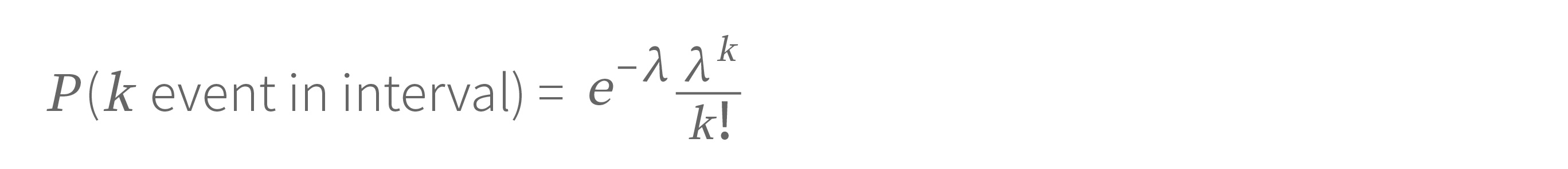
where
k = 1, 2, 3… (# of events)
e = 2.7182818284
λ = average # of continuous events in the given time interval
Let’s suppose a cloud storage service has an EC scheme of 17+3 with an AFR at 0.41% and MTTR of 156 hours, then the lambda equals: ((0.0041 * 20) / ((365 * 24) / 156)) = 0.00146027397.
The probability of 4 drives failing in 156 hours equals:
P = (2.7182818284-0.00146027397) * (0.001460273974) / (4 * 3 * 2 * 1) = 1.89187284e-13
In other words, (1 – P) represents the probability of the concurrent drive failures not occurring, which is 0.999999999999810812715 (12 nines). Since there are 56 “156 hour intervals” in a year, the annual durability actually equal: (1 – 1.89187284e-13)56 = 0.99999999999 (11 nines).
Synology C2 object durability
Synology goes for the second formula to calculate the durability of Synology C2 because we believe the Poisson distribution can more accurately reflect the durability level compared with the first formula. Drive failures should be seen as continuous events instead of discrete events. When one drive fails, the other drives installed at the same time are more likely to fail anytime soon.
Synology C2 now has an EC scheme of 12+3 with an AFR at 0.8% and MTTR of 286 (hr), which leads to 9 nines of data durability. We have put a lot of effort into making improvements on these key factors. There has been a marked decrease in the AFR (from 1.79% to 0.8%). Since it is our endless pursuit to provide reliable, durable cloud service to whoever entrusts us with their data, we are continually thinking about ways to enhance the durability level.
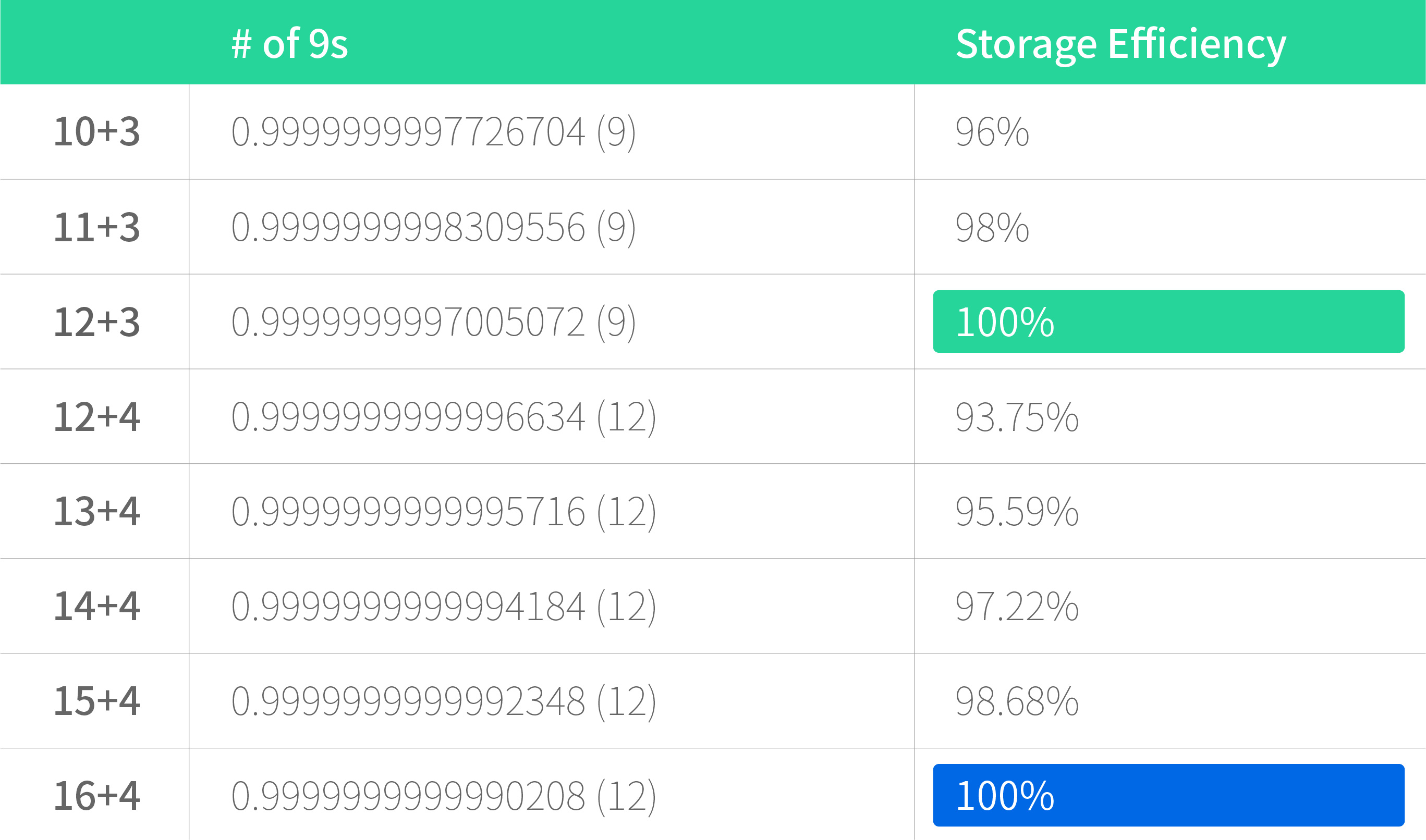
One of the options is to increase the data-stripe width. As shown from the table below, adding the parity fragments works out pretty well in terms of achieving more 9s. We also found that a stripe layout of 16+4 works best in that it significantly improves data durability from 9 nines to 12 nines without impairing storage efficiency. So, adding data pieces from 12+3 to 16+4 is what we’re going to do in the near future.
Real-life scenario
During the three weeks when we were expanding Synology C2 cloud storage, six drives failed, and two of them hit the same object. Luckily we survived it thanks to our fault-tolerant storage infrastructure.
Then a question arises as to how many nines are needed to withstand such simultaneous drive failures. The probability of concurrent drive failures is close to a RAID array that only has one parity drive. That’s why we suggest configuring RAID 6 if there are more than six drives within a volume. You will have two parity drives, which realizes higher data redundancy.
Hedge your bets against data loss
As mentioned earlier, there is not a consensus on the precise calculation of data durability, and to some extent, it has been abused by major cloud providers as a selling point for their cloud services by bragging some number of nines.
While it may sound great, no number of nines can prevent you from data loss. The truth is that two-thirds of data loss events are not caused by hardware failures (Backblaze). No matter how durable the storage infrastructure is, your data is still subject to human error anyway.
To minimize the risks of data loss, the best practices are to build a robust data protection strategy. You can’t be too careful when it comes to your mission-critical data. Be sure to adopt the 3-2-1 backup strategy to ensure the service availability and data integrity of your critical data. Keep three copies of your data, store them on two different media, with one stored off-site.

Want to extend data protection from on-premises to the cloud? Take the first step toward a solid backup plan with Synology C2 and tell us your thoughts in Community.
1 Data durability formula reference: the tech brief from Wasabi and the blog post from Backblaze.