ИИ-ассистенты незаметно стали частью повседневной работы. Они помогают составлять ответы, кратко пересказывать длинные цепочки писем, переводить контент для глобальных команд и превращать черновые заметки в тексты, готовые к отправке. Однако на вопрос «какая модель лучше?» неожиданно сложно ответить так, чтобы это отражало реальную рабочую практику. Восприятие бренда, различия в интерфейсах и даже один неудачный опыт могут быстро повлиять на мнение.
Поэтому мы провели небольшой внутренний эксперимент. В течение четырёх недель сотрудники Synology по всему миру использовали функции ИИ в Synology Office и MailPlus — нашем пакете Synology Office Suite, который позволяет организациям подключать выбранные ими LLM, сохраняя конфиденциальность данных благодаря слою деидентификации. Участники каждую неделю случайным образом получали одну из четырёх ведущих моделей (Claude, Gemini, GPT или Grok), при этом тестирование проводилось «вслепую»: никто не знал, какую именно модель он использует.
Мы сознательно не превращали эксперимент в лабораторное тестирование, поскольку стремились получить обратную связь из реальной повседневной работы, а не из строго контролируемых условий. Поэтому запросы не были стандартизированы, а задачи — регламентированы; участники выполняли практические задачи, такие как улучшение черновиков писем, проверка грамматики в отчётах, перевод презентаций для продаж и многое другое. После этого они заполняли короткий еженедельный опрос, в результате чего за четыре недели было собрано 147 ответов от сотрудников из десятков команд.
Что мы обнаружили
Три лидера показали практически одинаковые результаты. Claude, Grok и GPT оказались в пределах нескольких сотых балла по сводному показателю качества. Как и ожидалось для передовых LLM, различия между ними оказались минимальными. При этом более интересным наблюдением стало то, что, хотя GPT незначительно опередил Claude в итоговом рейтинге, он получил заметно больше негативных отзывов.
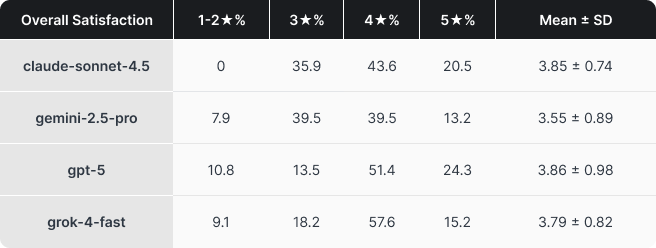
Сильные стороны моделей проявились гораздо отчётливее, чем их общий рейтинг. Claude показал лучшие результаты по точности и глубине — это особенно важно для задач, где критичны корректность и качество объяснений. Grok выделился по показателю, который мы обозначили как удовлетворённость при повторных запросах (Retry satisfaction), то есть по способности точно следовать инструкциям. Это важно, поскольку постоянные уточнения и правки быстро превращают помощника из полезного инструмента в источник раздражения. Gemini не продемонстрировал явных преимуществ ни по одному из показателей, что, вероятно, связано с тем, что в тесте использовалась более ранняя версия (на момент начала исследования Gemini 3 ещё не была доступна). Ещё раз подчеркнём: это не было научным исследованием, однако полученные результаты оказались весьма показательными.
Где возникали сложности
Качественная обратная связь и комментарии участников показали достаточно чёткую картину того, что именно замедляет работу пользователей:
-
Недостаточное следование инструкциям, необходимость множества итераций для достижения нужного тона, структуры и корректности
-
Ответы, которые технически были корректными, но слишком длинными или излишне осторожными, что создавало дополнительную нагрузку и снижало реальную экономию времени.
-
Проблемы с контекстом, когда модель делала выводы на основе некорректной информации (например, не учитывала, что время встречи было изменено в последующих письмах цепочки).
Некоторые из этих аспектов сложно количественно оценить, однако именно они определяют, воспринимается ли ассистент как инструмент, экономящий время, или как бесполезная функция. Даже при «слепом» тестировании проявлялись устойчивые различия в поведении моделей.
Некоторые модели по умолчанию создавали более длинные черновики, даже при запросе на краткость, что замедляло рабочие процессы, особенно при написании писем, где важны чёткие и лаконичные формулировки. Другие склонялись к более осторожным, «обтекаемым» ответам в неоднозначных ситуациях, снижая риск ошибок или спорных утверждений, но одновременно вызывая раздражение у пользователей, которым требовались чёткие рекомендации или однозначные формулировки.
Стоимость
Ещё одной причиной проведения этого пилота стало то, что фактическую стоимость использования предсказать довольно сложно. Поведение потребления токенов существенно различается между моделями, и реальные затраты могут быстро отклоняться от ожидаемых, если ориентироваться только на цену за токен.
В наших журналах использования мы увидели явные различия в эффективности расходования токенов между моделями, даже при использовании одинаковых запросов и исходных файлов. В тестах режим рассуждений был в основном отключён или установлен на минимальный уровень, однако поведение моделей всё равно существенно различалось — во многом из-за их изначально недетерминированной природы.
Мы также провели отдельный короткий тест для оценки эффективности, и его результаты в целом совпали с результатами основного исследования по всей компании. Проще говоря, различия в стоимости и эффективности между моделями оказались весьма существенными. Несмотря на то, что Claude в целом получил наилучшие отзывы, остаётся вопрос — оправдывает ли он стоимость, превышающую более чем в два раза цену Gemini или GPT? При этом даже не совсем корректно включать Grok в это сравнение.
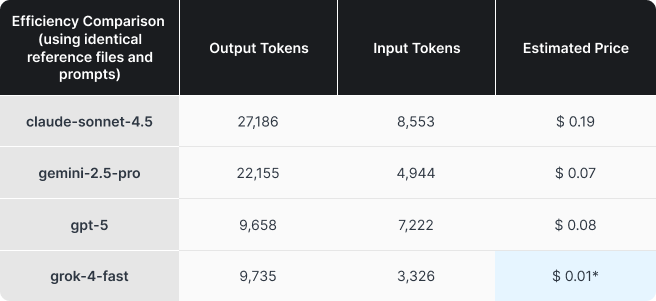
*Округлено в большую сторону
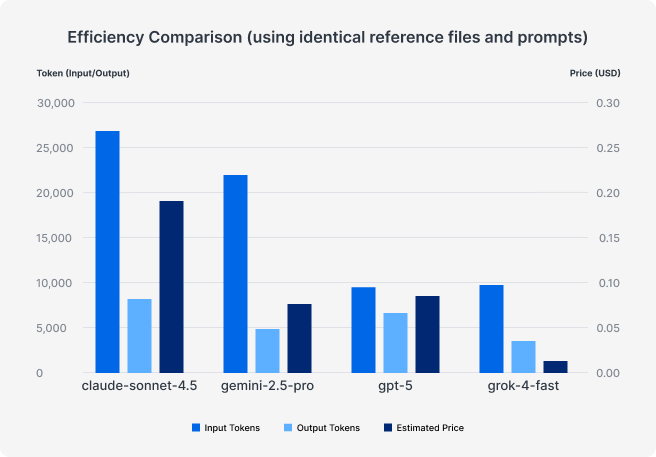
Практический вывод: затраты могут существенно различаться. Как и при работе с ИТ-поставщиками, важно отслеживать и регулярно оценивать соотношение качества и стоимости используемых сервисов. Модели ИИ сегодня развиваются с чрезвычайной скоростью, что делает ещё более важным и полезным постоянное отслеживание этих изменений.
Что это означает для компаний, внедряющих ИИ
Основной вывод прост: ИИ — это не инструмент, который можно один раз настроить и забыть. Наш тест длился всего четыре недели, и даже за это время провайдеры выпустили значимые обновления, повлиявшие на поведение моделей, качество и стоимость. Если вы внедряете ИИ в ключевые бизнес-процессы, необходимо иметь лёгкий механизм регулярной проверки того, насколько ваши исходные предположения по-прежнему актуальны для вашей среды.
ИИ уже демонстрирует значительный потенциал для выполнения рутинных интеллектуальных задач, особенно в области написания текстов, суммаризации и перевода. При этом ключевыми факторами остаются количество повторных попыток, точность результатов и то, насколько сотрудники уверены в том, что могут использовать полученный черновик с минимальными правками — именно это в итоге определяет реальную экономию времени.
Наконец, стоит отметить, что сделало подобную оценку возможной: пилот был проведён в среде Synology Office и MailPlus с активным слоем деидентификации между пользовательским контентом и провайдером модели. Эффективность бизнес-процессов зависит не только от самой LLM, но и от выбора системы, которая интегрируется в рабочие процессы сотрудников и соответствует политикам безопасности данных компании. Именно это лежит в основе Synology AI Console — платформы, разработанной для того, чтобы организации могли развиваться вместе с экосистемой ИИ, сохраняя при этом безопасность своих данных.
Готовы сократить разрыв между продуктивностью на базе ИИ и безопасностью данных?
Ознакомьтесь с пакетом Synology Office Suite с поддержкой ИИ
Материал ориентирован на аудиторию стран СНГ.