Asystenci AI stali się niemal niewidzialną częścią codziennej pracy. Tworzą szkice odpowiedzi, podsumowują długie wątki mailowe, tłumaczą treści dla globalnych zespołów i zamieniają chaotyczne notatki w coś, co faktycznie można wysłać. Jednak pytanie „który model jest najlepszy?” wcale nie jest proste – opinie szybko mogą zostać zniekształcone przez markę, różnice w interfejsie czy jedno nieudane doświadczenie.
Postanowiliśmy przeprowadzić mały, wewnętrzny eksperyment. Przez cztery tygodnie pracownicy Synology na całym świecie korzystali z funkcji AI w Synology Office i MailPlus, naszej platformie biurowej, która pozwala firmom wybrać własny model LLM, jednocześnie zachowując prywatność danych dzięki warstwie de-identyfikacji. Każdy uczestnik losowo otrzymywał jeden z czterech wiodących modeli w danym tygodniu (Claude, Gemini, GPT lub Grok), a test był całkowicie ślepy – nikt nie wiedział, z którym modelem pracuje.
Nie chcieliśmy przekształcać tego w laboratoryjne benchmarki – zależało nam na realnym feedbacku z codziennych zadań. Krótka uwaga: polecenia nie były standaryzowane, a zadania niekontrolowane. Ludzie wykonywali jednak prawdziwą pracę – poprawiali szkice maili, sprawdzali gramatykę raportów, tłumaczyli prezentacje sprzedażowe i wiele więcej. Na koniec wypełniali krótki, tygodniowy ankietowy feedback. W ciągu czterech tygodni zebraliśmy 147 odpowiedzi obejmujących dziesiątki zespołów.
Co pokazują wyniki
Trzy najlepsze modele osiągnęły niemal identyczne rezultaty.
Claude, Grok i GPT różniły się w łącznej ocenie jakości dosłownie o ułamki punktu. Jak można było się spodziewać po czołowych modelach LLM, różnice między nimi są niewielkie.
Ciekawsze jest jednak to, że choć GPT minimalnie wyprzedził Claude w końcowym wyniku, zebrał przy tym wyraźnie więcej negatywnych opinii.
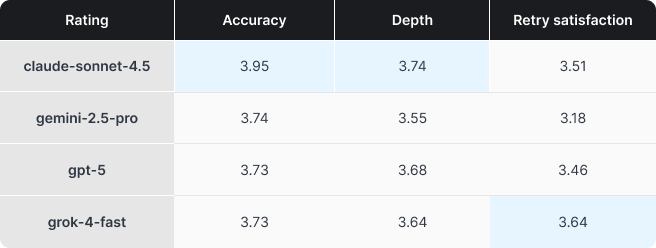
Mocne strony modeli widać wyraźniej niż sam ranking
Znacznie więcej niż końcowa kolejność mówi o nich to, w czym są naprawdę dobre. Claude osiągnął najlepsze wyniki w obszarach dokładności i głębi odpowiedzi, co czyni go solidnym wyborem tam, gdzie liczy się precyzja i sensowne wyjaśnienie.
Grok wyróżnił się w kategorii, którą nazwaliśmy „satysfakcją z ponownych prób”. W praktyce chodzi o to, jak dobrze model rozumie i realizuje polecenia. To istotne, bo ciągłe poprawianie i doprecyzowywanie odpowiedzi bardzo szybko zamienia pomocne narzędzie w źródło frustracji.
Gemini nie dominował w żadnym z badanych obszarów, co najpewniej wynika z faktu, że w tym zestawieniu był najstarszym modelem. W momencie startu testu Gemini 3 nie był jeszcze dostępny.
To nie było badanie o charakterze naukowym, ale mimo to przyniosło kilka ciekawych obserwacji.
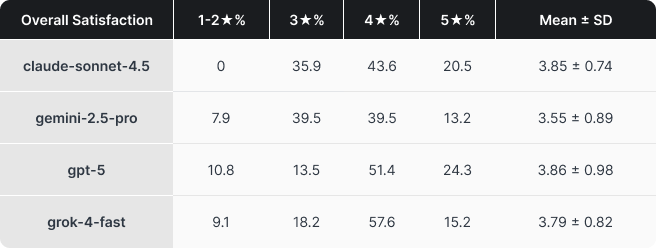
Gdzie pojawiały się problemy
Zebrane opinie i komentarze bardzo jasno pokazały, co w praktyce spowalnia pracę:
- Niedokładne realizowanie poleceń i konieczność wielu iteracji, zanim udało się uzyskać właściwy ton, strukturę i poprawność
- Odpowiedzi poprawne merytorycznie, ale zbyt długie lub zachowawcze, które zamiast oszczędzać czas generowały dodatkową pracę
- Problemy z kontekstem, gdy model opierał się na błędnych założeniach, na przykład nie wychwytywał zmiany godziny spotkania w dalszej części wątku mailowego
Trudno przełożyć te aspekty na konkretne wskaźniki, ale to właśnie one decydują, czy asystent faktycznie usprawnia pracę, czy jest tylko ciekawostką. Nawet w ślepym teście różnice w zachowaniu modeli były wyraźnie odczuwalne.
Część modeli domyślnie tworzyła zbyt rozbudowane pierwsze wersje odpowiedzi, mimo próśb o zwięzłość. To szczególnie problematyczne w komunikacji mailowej i codziennym pisaniu, gdzie liczy się klarowność i konkret.
Inne z kolei skłaniały się ku bardziej asekuracyjnym odpowiedziom w niejednoznacznych sytuacjach. Z jednej strony zmniejszało to ryzyko błędu lub kontrowersji, z drugiej potrafiło frustrować użytkowników oczekujących jasnej rekomendacji lub konkretnego stanowiska.
Koszty
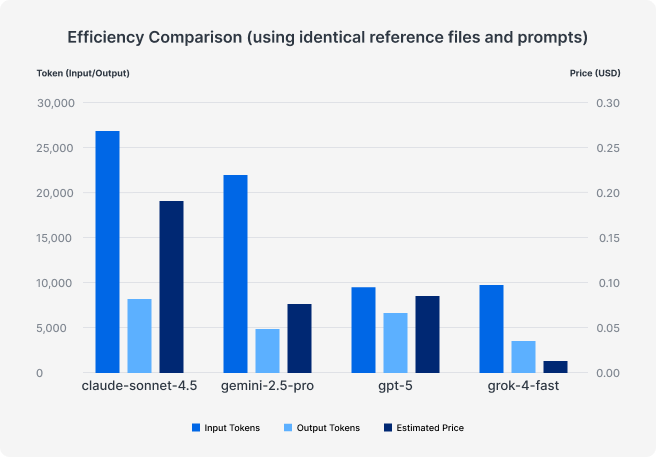
Jednym z powodów przeprowadzenia pilotażu była trudność w realnym oszacowaniu kosztów. Zużycie tokenów potrafi znacząco różnić się między modelami, a faktyczne wydatki szybko odbiegają od tego, co sugerują same stawki za token.
W naszych logach wyraźnie było widać różnice w efektywności wykorzystania tokenów, nawet przy identycznych promptach i tych samych materiałach wejściowych. Testy prowadziliśmy przy minimalnym poziomie „rozumowania”, ale mimo to zachowanie modeli potrafiło się istotnie różnić. To naturalne, bo modele językowe z definicji nie działają w pełni deterministycznie.
Przeprowadziliśmy też krótszy, dodatkowy test skupiony wyłącznie na efektywności i jego wyniki potwierdziły wcześniejsze obserwacje. Wniosek jest prosty: różnice w kosztach i wydajności są zauważalne i mają znaczenie.
Choć Claude zebrał najlepsze opinie jakościowe, pojawia się pytanie, czy uzasadnia to ponad dwukrotnie wyższą cenę względem Gemini czy GPT. A w przypadku Groka porównanie kosztowe nie jest do końca miarodajne.
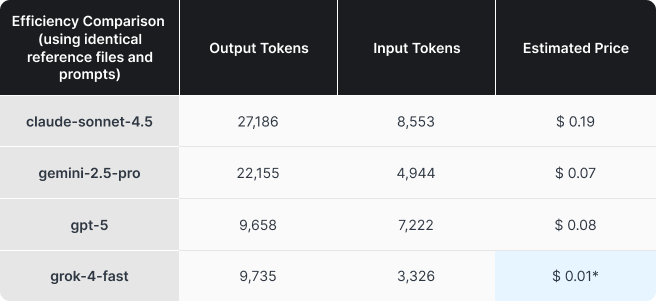
*Zaokrąglone w górę
Co to oznacza dla firm wdrażających AI
Najważniejszy wniosek jest prosty: AI to nie jest rozwiązanie typu „wdrożyć i zapomnieć”. Nasz test trwał zaledwie cztery tygodnie, a nawet w tym czasie dostawcy wprowadzali istotne zmiany wpływające na działanie modeli, ich jakość i koszty. Jeśli AI trafia do kluczowych procesów, warto mieć lekki, ale regularny sposób weryfikacji, czy przyjęte założenia nadal się sprawdzają w praktyce.
Już dziś AI dobrze odnajduje się w codziennej pracy z wiedzą, szczególnie przy tworzeniu treści, podsumowaniach i tłumaczeniach. Największe znaczenie mają liczba koniecznych poprawek, dokładność oraz to, czy pracownicy czują się na tyle pewnie, by wykorzystać wygenerowany materiał przy minimalnych zmianach i realnie oszczędzić czas.
Warto też zwrócić uwagę na to, co umożliwiło przeprowadzenie takiego testu. Pilotaż realizowaliśmy w środowisku Synology Office i MailPlus, z aktywną warstwą de-identyfikacji oddzielającą dane użytkowników od dostawcy modelu. Produktywność nie zależy wyłącznie od samego modelu, ale również od systemu, który wpisuje się w codzienny workflow zespołu i spełnia firmowe wymagania w zakresie bezpieczeństwa danych. To właśnie fundament Synology AI Console, platformy zaprojektowanej tak, aby wspierać organizacje w rozwoju wraz z ekosystemem AI, bez kompromisów w kwestii ochrony danych.
Gotowi połączyć produktywność napędzaną AI z bezpieczeństwem danych?
Sprawdź możliwości pakietu Synology Office Suite z funkcjami AI.
Kliknij, aby skonsultować się z ekspertem Synology i przetestować nasze rozwiązanie za darmo tutaj.